Last updated: March 4, 2024
Open-source and local large language models (LLMs) really start to shine when customized for your personal needs. One way to improve an LLM's performance on a specific task is to fine-tune the model.
There are numerous ways to fine-tune a model, this guide will outline my process of creating a low rank adaptation (LoRA) on Apple hardware with MLX.
Overview:
Problem
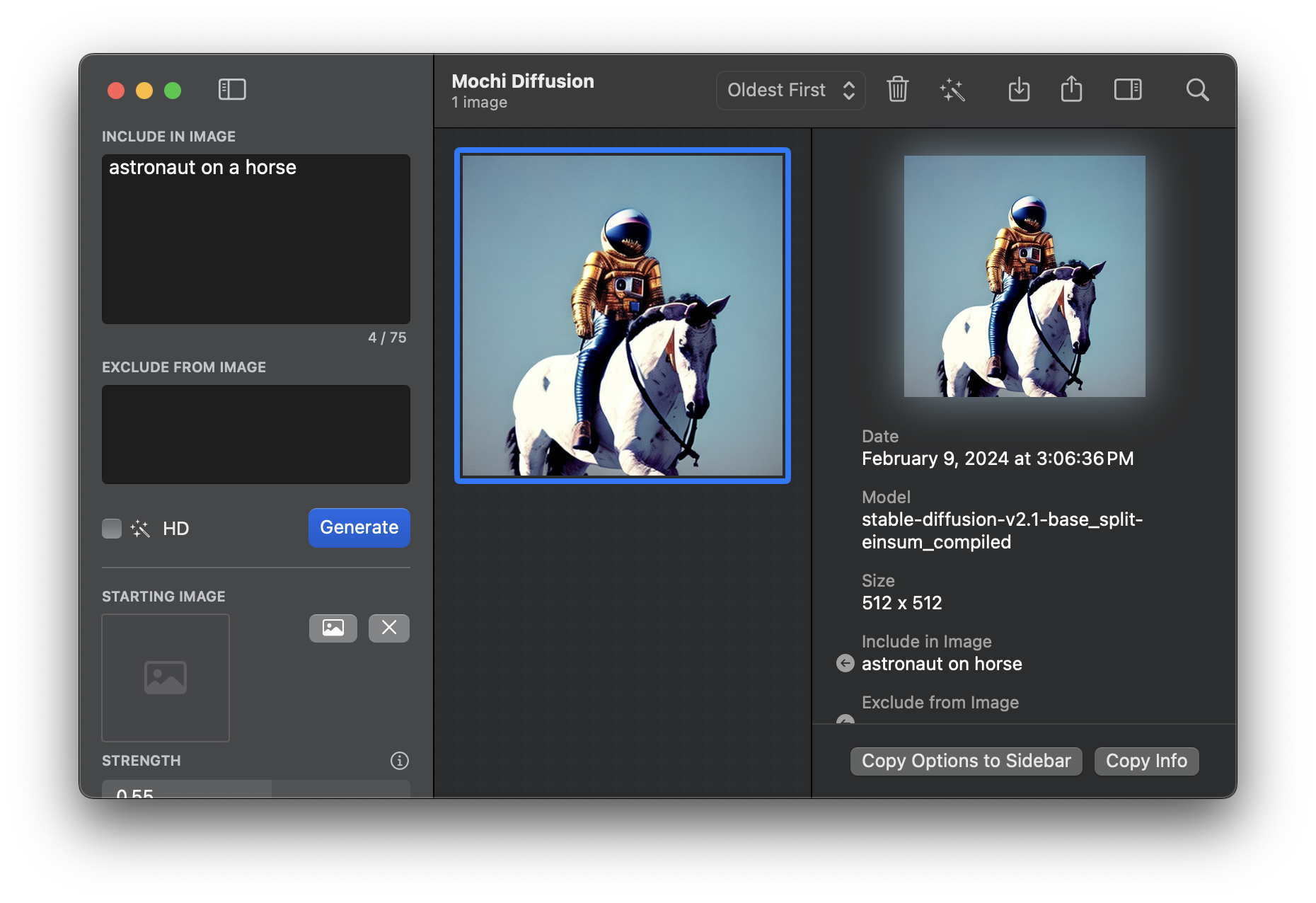 I am using Mochi Diffusion to run Stable Diffusion locally and generate images. The challenge? My basic prompts yield uninspiring results.
I am using Mochi Diffusion to run Stable Diffusion locally and generate images. The challenge? My basic prompts yield uninspiring results.
Model Evaluation
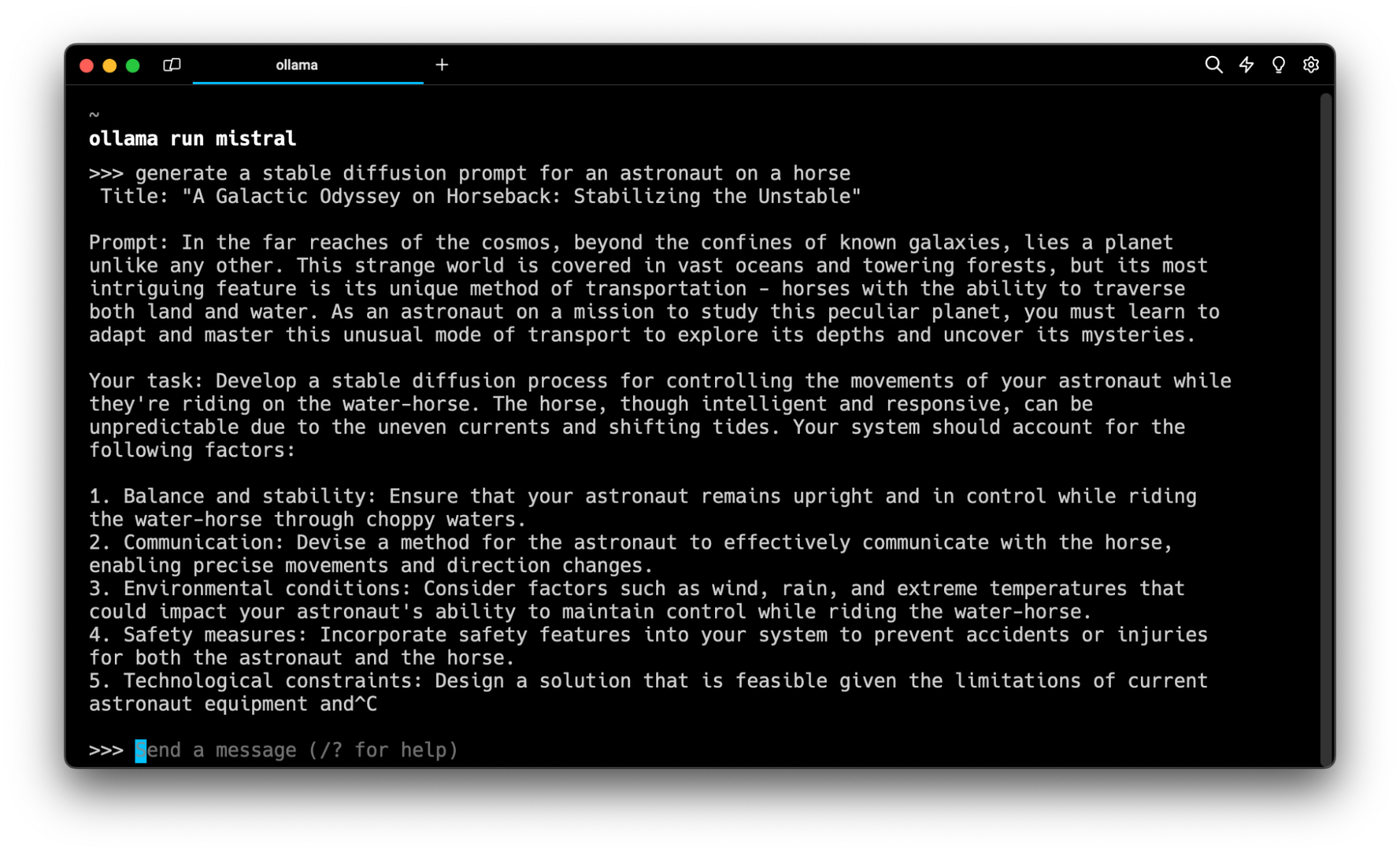 I need to fine-tune a model to get the output I want. So it's time to choose a model to fine-tune. Generating a Stable Diffusion prompt is a fairly constrained task so a smaller model will be sufficient. I'll fine-tune on Mistral's 7 billion parameter model.
I need to fine-tune a model to get the output I want. So it's time to choose a model to fine-tune. Generating a Stable Diffusion prompt is a fairly constrained task so a smaller model will be sufficient. I'll fine-tune on Mistral's 7 billion parameter model.
Dataset
A good dataset is the key to getting good results from a fine-tune. Sometimes this will mean building a dataset in the format you need. If you're lucky a high quality dataset will already exist. In this case a high-quality instructional dataset for Stable Diffusion prompts already exists on Hugging Face.
I need the dataset in jsonl format so I convert the parquet file using parquet-viewer.
Fine-Tuning
Split the data into a training and verification dataset. I do this using a simple python script:
def split_jsonl_file(input_filename):
# Read all lines from the input file
with open(input_filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
# Calculate split index for 80% of data
split_index = int(len(lines) * 0.8)
# Write the first 80% of lines to train.jsonl
with open('train.jsonl', 'w', encoding='utf-8') as train_file:
train_file.writelines(lines[:split_index])
# Write the remaining 20% of lines to valid.jsonl
with open('valid.jsonl', 'w', encoding='utf-8') as valid_file:
valid_file.writelines(lines[split_index:])Clone the MLX examples repo and install the lora example requirements.
$ git clone https://github.com/ml-explore/mlx-examples.git
$ cd lora/
$ pip install -r requirements.txtResults
$ ollama run brxce/stable-diffusion-prompt-generator
>>> an astronaut on a horse
Astronaut on a horse, ultra realistic, digital art, concept art, smooth, sharp focus, illustration, highly detailed, cinematic lighting, in the style of Tom Rockwell and Zdenko and Laura Cok