Recently I've been working on Ollama so I've been spending a lot of time thinking about running large language models (LLMs) on local systems and how to package them into applications. A typical experience for most desktop applications that use LLMs would be either to plug in your OpenAI API key or build a Python project from source. These approaches work as a proof of concept but they require some base knowledge that many users will not have. The experience I am after is a single click application download which just runs.
The Plan
Here are my initial goals with the project:
- One click download and run.
- No external dependencies.
- Minimal application file size.
- A simple LLM version control and distribution system.
- Build and release for all major operating systems.
- Take advantage of running locally with the local file system being available.
- No settings exposed to the user. The LLM should just run optimally on their system without the need for intervention.
- Batteries included, but swappable. For power users they should have advanced configuration available that allows them to customize the LLM that powers the app as they would like.
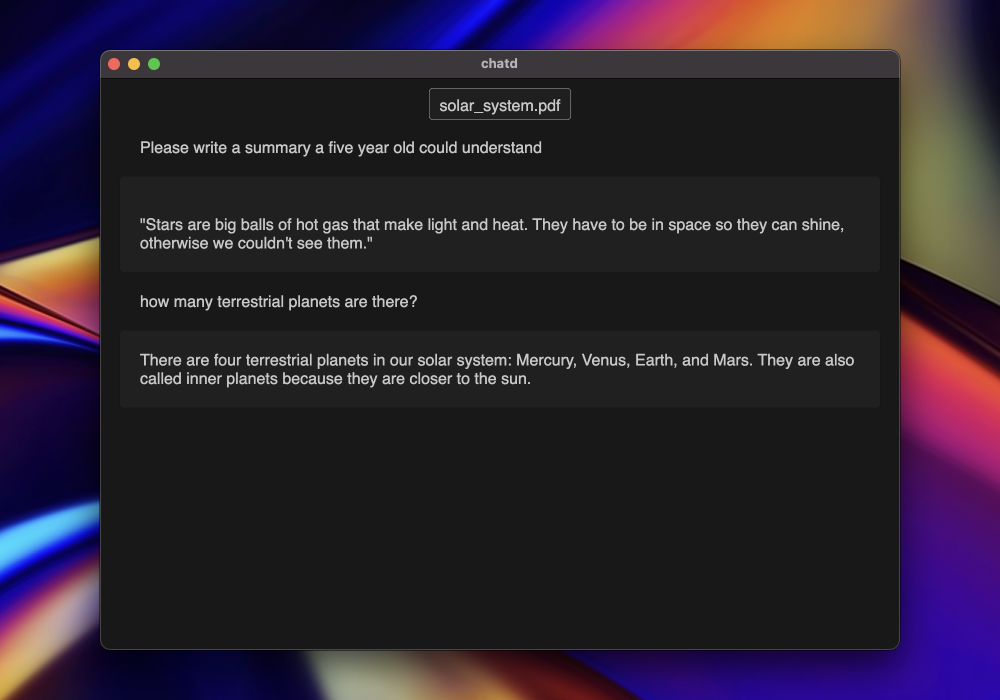
With all that in mind I decided to build "chatd" a desktop app that allows you to chat with your documents. This is a common LLM application use-case, but I don't believe there is a great simple option for non-technical end-users. It also takes advantage of the fact that the application has easy access to the filesystem.
In the spirit of keeping things simple I wanted all the project code to be contained within one app that can be deployed on any operating system. This pretty quickly narrowed down my options to Electron or Tauri. I decided to go with Electron as I was more familiar with the ecosystem.
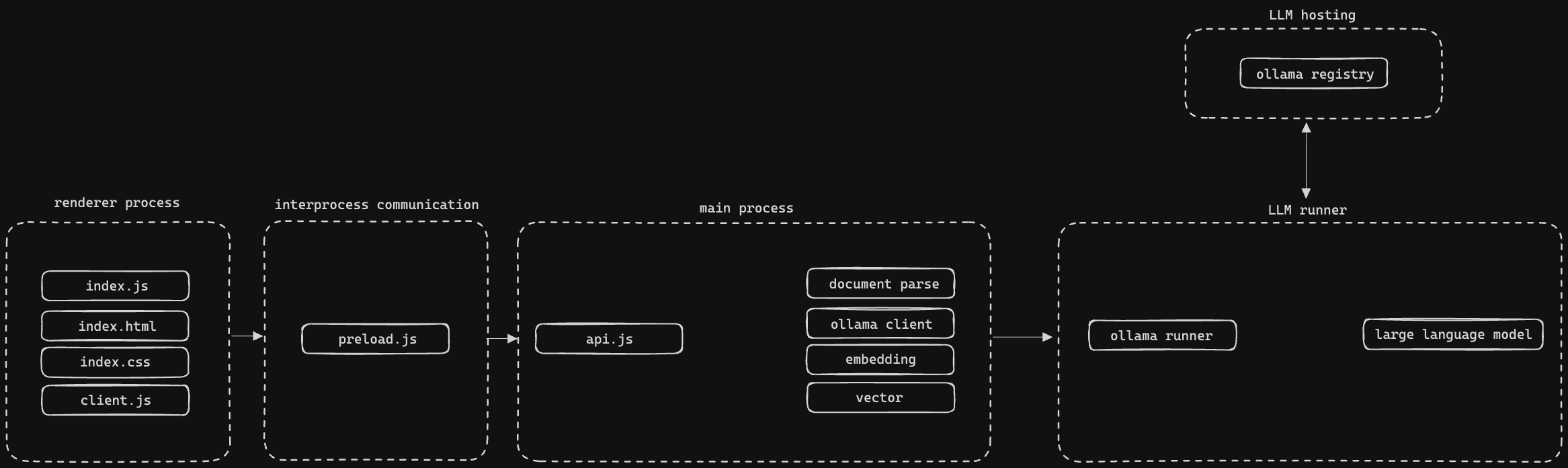
Architecture
 Click here to see a larger version of this image.
Click here to see a larger version of this image.
{kind=link}
The project has four distinct sections. Rendering, interprocess communication, the main process, and the LLM runner.
Rendering and Interprocess Communication
The rendering is done in typical HTML, CSS, and JavaScript. When the user takes an action that requires processing this is sent through interprocess communication to the main process. This allows executing code which has access to the actual host system.
Main Process
The main process consists of some custom document processing (side note: someone please make a standard JavaScript library for the general document processing use-case) which then feeds the extracted data into transformers.js. The transformers.js library is a project maintained by Hugging Face that lets you run models in the browser using the ONNX runtime. This can be super fast. Finally I store the vectors in memory as there was no in-memory vector database that met my needs yet.
LLM Runner
With all this information processed I used Ollama as the way to package and distribute the LLM that will power the interaction. Currently most users run Ollama as a stand-alone application and send queries to it, but it is also possible to package it directly into your desktop application and orchestrate it. I added Ollama executables for each operating system to their corresponding packages and wrote some JavaScript code to orchestrate the use of the executable.
This ended up being really convenient because not only was I able to leverage Ollama as a dependable system to run the LLM. It also gave me an easy system for distributing the LLM outside of the Electron package. Adding the LLM to the Electron application package itself would have meant a massive initial download (over 4GB), and would have locked the user into only using the model I shipped with chatd. On top of that, using Ollama's distribution system I can also update or modify the model without doing a new application release. I can make the changes, push the model to the ollama.ai registry, and users will get the update next time they start the app.
Leveraging Ollama also keeps the user experience simple while still allowing power users to swap out the model powering the application if they want to. Early local LLM adopters (and the Ollama users I interact with) are interested in how things work and want to be on the cutting-edge with the latest models. Although Ollama is packaged into chatd it can detect if Ollama is already running. In this case it exposes additional settings to the user that let them configure chatd as they see fit and swap out the model. It also means users don't have to download models again if they already have.
Results
I've been showing chatd to some friends that are outside the typical ChatGPT user-base and they have been really receptive. Seeing AI run simply and locally on their computer is mind-blowing to them, and they have quickly seen the potential in giving this local chatbot access to their files. I'm looking forward to improving the experience and I hope we can see a new wave of desktop applications making LLMs easy.
You can check out the chatd project here: chatd.ai